- Published on
Retry and Dead Letter Queue in Kafka
- Author

- Name
- Abidin Özdurmaz
- @abidino
Introduction
In this article, I’ll walk you through setting up a retry mechanism in Kafka and explain the concept of a Dead Letter Queue (DLQ). We’ll also explore scenarios where these can be effectively used.
Kafka is a popular message broker widely used in software projects. It allows us to send messages to specific topics, with consumers processing these messages or triggering other events. This article focuses on handling errors during message processing.
Customizing the Retry Count
By default, when Kafka fails to process a message, it repeatedly attempts to do so, which can block subsequent messages and halt system progress.
There are various methods available to solve this problem.
If an error occurs while processing our messages, we can customize the maximum number of retries. In a Spring Boot project, this can be configured as follows:
@Configuration
@EnableKafka
public class KafkaConfig {
@Bean
public ConcurrentKafkaListenerContainerFactory<?, ?> kafkaListenerContainerFactory(ConsumerFactory<Object, Object> consumerFactory) {
ConcurrentKafkaListenerContainerFactory<Object, Object> factory = new ConcurrentKafkaListenerContainerFactory<>();
factory.setConsumerFactory(consumerFactory);
factory.setCommonErrorHandler(defaultErrorHandler());
return factory;
}
@Bean
public DefaultErrorHandler defaultErrorHandler() {
// Retry 5 Times with 1000ms Intervals
FixedBackOff fixedBackOff = new FixedBackOff(1000L, 5);
return new DefaultErrorHandler((record, exception) -> {
if (exception instanceof SerializationException) {
System.err.println("Serialization exception for record: " + record);
}
}, fixedBackOff);
}
}
This is an effective way to handle transient issues during message processing on the consumer side.
However, if the issue is more persistent (such as an external service being unavailable or a database problem) this method may still fail after five attempts. Increasing the retry count or extending the interval might help but could lead to a message backlog.
Retry Topic
Instead of waiting for retries to complete, we can consider the message processed and send it to a newly created Retry Topic. This allows the consumer to continue processing other messages while the Retry Topic handles the retries.
Application Scenario
To better visualize this, let’s imagine the following setup:
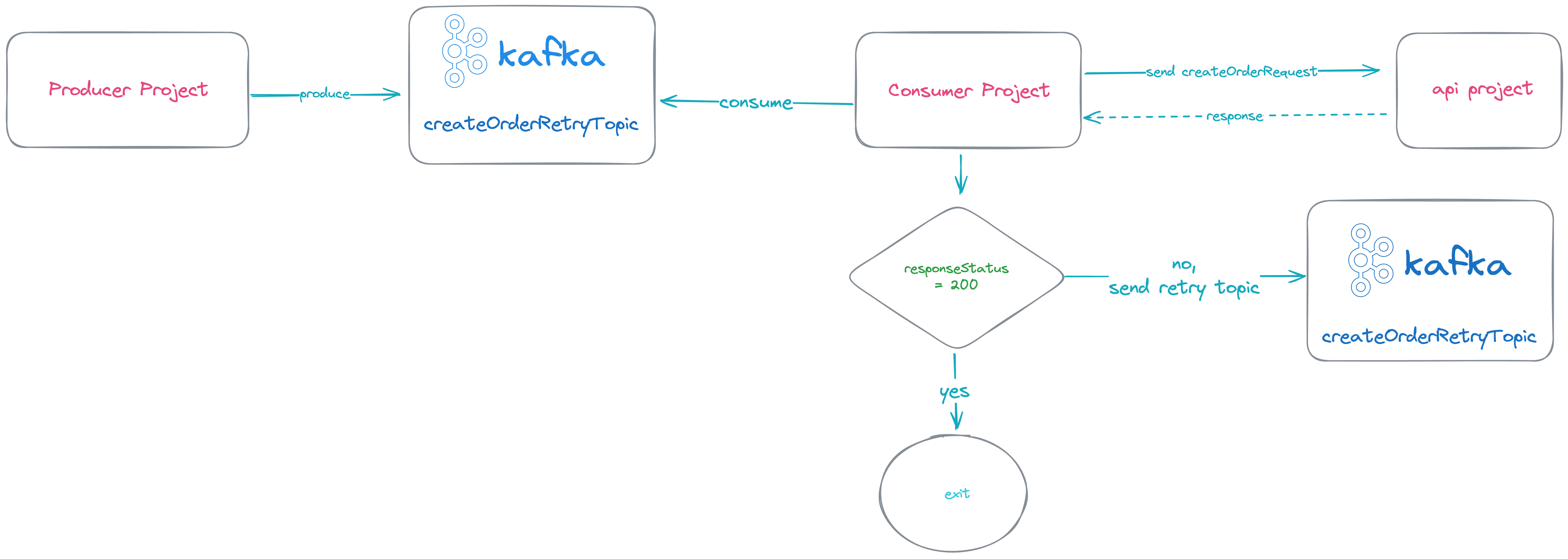
Consider three projects: Producer, Consumer, and an API project. After the Producer sends a new message, the Consumer receives it and makes a request to the API project. If an error occurs, the message is sent to the Retry Topic, and the consumer moves on to process the next message.
@Service
public class KafkaListenerExample {
@KafkaListener(topics = "createOrder", groupId = "test_group_id")
public void listenCreateOrder(String message) {
try {
sendApiRequest(message);
} catch(Exception e){
sendRetryTopic(message);
}
}
@KafkaListener(topics = "createOrderRetry", groupId = "test_group_id")
public void listenCreateOrderRetry(String message) {
sendApiRequest(message);
}
}
With this implementation, the message sent to the Retry Topic will be retried. If successful, the process is completed. If it fails, we can use Kafka’s Header structure to store retry count information and continue retrying. But what if it still fails? This is where the Dead Letter Queue comes into play.
Dead Letter Queue
A Dead Letter Queue (DLQ) in Kafka is essentially a topic dedicated to storing messages that have failed processing despite multiple retries. These messages can then be handled according to specific needs.
For instance, we can have a Consumer project that listens to the DLQ, logs the failed messages, and sets up alerts in ElasticSearch, or stores them in a database for reference. This approach helps to minimize data loss by retaining information about failed events. Let’s illustrate this workflow.
Application Scenario
- If the
Consumerencounters an error while processing a message, it sends the message to theRetry Topic.
- The message sent to the
Retry Topicis processed, and if an error occurs, the retryCount is incremented. If the retryCount reaches 5, the message is sent to theDead Letter Queue; otherwise, it is sent back to the Retry Topic.
- Finally, a
Consumerlistening to theDead Letter Queuelogs the message and records the failed event in the database.

Example Code:
@Service
public class KafkaListenerExample {
private int maxRetryCount = 5;
@KafkaListener(topics = "createOrder", groupId = "test_group_id")
public void listenCreateOrder(String message) {
try {
sendApiRequest(message);
} catch(Exception e) {
int retryCount = 0;
sendRetryTopic(message, retryCount);
}
}
@KafkaListener(topics = "createOrderRetry", groupId = "test_group_id")
public void listenCreateOrderRetry(String message,
@Header(name = "retryCount") Integer retryCount) {
try {
sendApiRequest(message);
} catch(Exception e) {
retryCount++;
if (retryCount == maxRetryCount) {
sendDlTopic(message);
return;
}
sendRetryTopic(message, retryCount);
}
}
@KafkaListener(topics = "createOrderDeadLetter", groupId = "test_group_id")
public void listenCreateOrderDL(String message) {
log.warning("new event received in dl {}", event);
insertDb(event);
}
}
Beyond the Solution
Beyond the provided solution, several improvements can be made. For instance, instead of immediately retrying failed messages, you could prefer to process them every 5 minutes. In Kafka, you can set up a cron job to ensure the Consumer runs every 5 minutes to handle such tasks.
Conclusion
As user numbers for applications continue to grow, setting up a system that minimizes wait times, easily identifies errors, and quickly detects issues through notifications is invaluable. I hope this method helps solve your problems or provides a new perspective for addressing specific issues. Thank you for reading.
Best of luck to everyone. ✌🏼